최근 진행한 프로젝트에서 시각화를 많이 다루어 이번 포스트에서는 시각화를 주제로 제가 배운 것들을 공유하겠습니다. 시각화를 하면 할수록 화려한 plot을 그리기보다 본래 목적에 맞게 명확한 전달성에 가치를 두는 것이 맞다고 생각해 최대한 심플하게 전하는데 의미를 두었습니다.
시각화를 접하기 가장 좋은 첫 번째 방법은 데이터의 분포를 간단하게 나타내는 것입니다. 분석하고 싶은 데이터가 있다면 해당 feature는 어떻게 이루어져 있는지 시각화를 통해 알아보는 것입니다.
barplot

가장 손쉽게 다룰 수 있는 plot중 bar plot은 자주 사용되는 방법 중 하나입니다. 위의 그래프는 영화 데이터 분석 중 영화 발매 연도를 시각화한 것입니다. 코드와 같이 보겠습니다.
plt.figure(figsize=(18,12))
plt.xticks(fontsize=12,rotation=90)
sns.countplot(x='release_year', data=train)
먼저 첫번째 라인인 figure은 그래프의 크기를 나타냅니다. 데이터가 다양할수록 복잡해지니 위와 같은 그래프는 어느 정도 크게 그려주는 것이 좋습니다. 두 번째 라인은 x축의 설정을 나타냅니다. 연도의 폰트 사이즈를 정하고 폰트가 겹치지 않게 90도로 회전해 주었습니다.(x축과 y축을 바꾸어 표현하는 방법도 좋은 방법입니다.!) 마지막 세 번째 라인은 위의 두 설정을 가지고 그래프를 그리는 부분이 될 텐데요. train(영화 data)이라는 data에서 release_year(발매 연도)이라는 column을 불러와 그래프를 그려주었습니다.
kdeplot
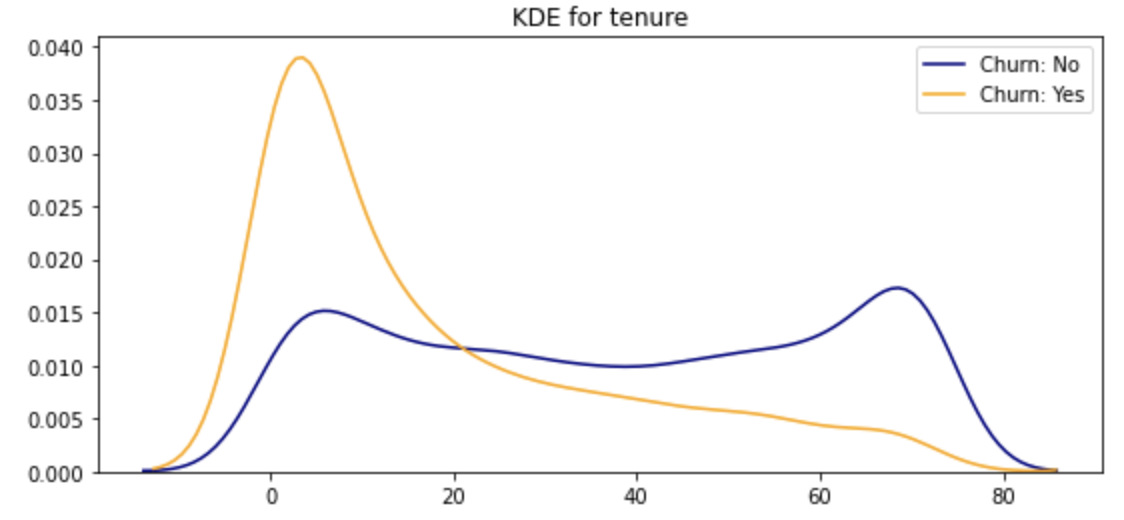
kdeplot의 장점은 많은 특성을 하나의 그래프로 표현할 수 있다는 것입니다. 고객들이 한 기업의 서비스를 이용하는 월 수만을 그래프로 표현할 수 있었지만 분석의 주된 목표가 이탈 고객을 파악하는 데에 있었기 때문에 kdeplot을 통해 이탈 고객과 남은 고객을 비교할 수 있었습니다.
def kdeplot(feature):
plt.figure(figsize=(9, 4))
plt.title("KDE for {}".format(feature))
ax0 = sns.kdeplot(df[df['Churn'] == 'No'][feature].dropna(), color= 'navy', label= 'Churn: No')
ax1 = sns.kdeplot(df[df['Churn'] == 'Yes'][feature].dropna(), color= 'orange', label= 'Churn: Yes')
kdeplot('tenure')
distplot
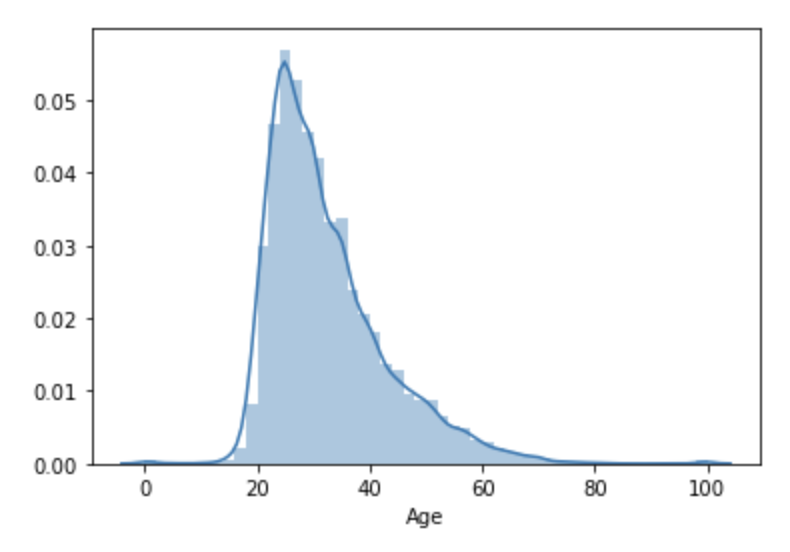
distplot은 cardinality(집합원의 갯수)가 높은 즉, value의 중복도가 낮은 값들이 많이 존재할 때 (나이와 가격 등은 수많이 존재할 수 있습니다.) 어떤 분포를 이루고 있는지 쉽게 알 수 있습니다.
sns.distplot(df['Age'])
parameter 'hue'.
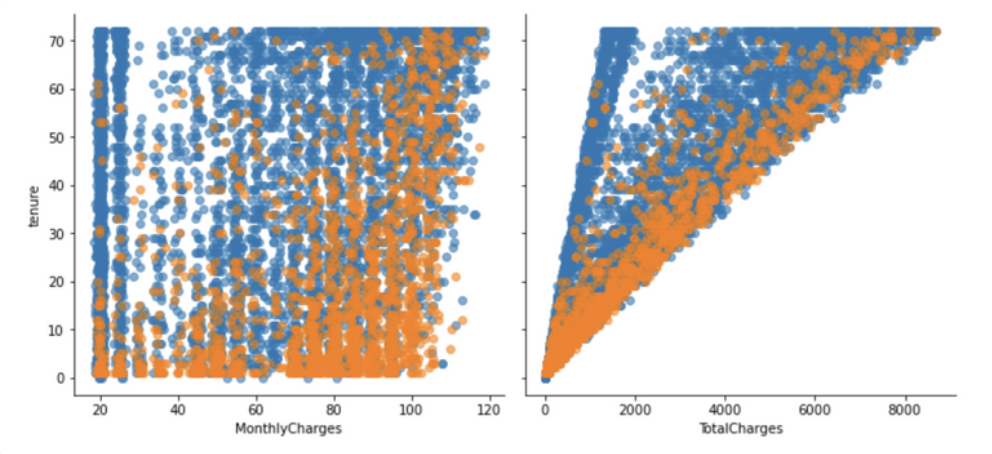
g = sns.PairGrid(df, y_vars=["tenure"], x_vars=["MonthlyCharges", "TotalCharges"], height=4.5, hue="Churn", aspect=1.1)
ax = g.map(plt.scatter, alpha=0.6)
plot을 그릴 때 parameter인 hue를 추가하면 비교하는 싶은 대상을 더욱 효과적으로 시각화할 수 있습니다. PairGrid는 subplot을 만들어 2개의 feature에 비교 대상인 feature를 hue 통해 추가합니다.
pie
마지막으로 pie plot은 각각의 value가 그 feature에서 어느 정도를 차지하고 있는지 그 비율을 한 눈에 알아보기 좋은 plot입니다. 하지만 value가 많았지만 비중이 작은 value는 구분하기 힘들기 때문에 value가 어느 정도 제한되어 있는 것이 좋습니다.(low cardinality)
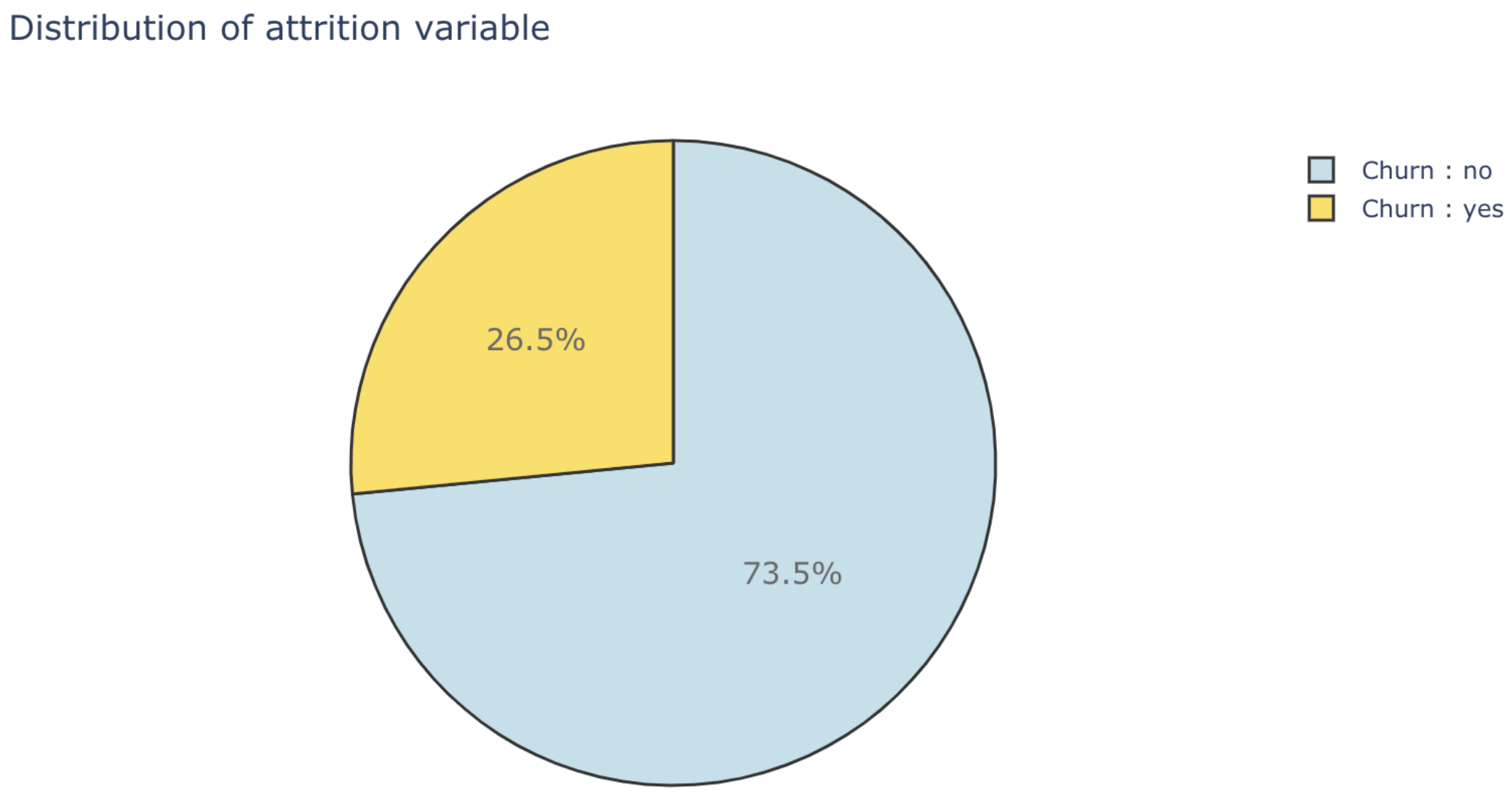
trace = go.Pie(labels = ['Churn : no', 'Churn : yes'], values = data['Churn'].value_counts(),
textfont=dict(size=15), opacity = 0.8,
marker=dict(colors=['lightblue','gold'],
line=dict(color='#000000', width=1.5)))
layout = dict(title = 'Distribution of attrition variable',
autosize = False,
height = 500,
width = 800)
fig = dict(data = [trace], layout=layout)
iplot(fig)
'Python skills for Data Analysis' 카테고리의 다른 글
| [Functions] apply(lambda x :) examples (0) | 2020.08.15 |
|---|---|
| [Functions] groupby examples (0) | 2020.08.14 |
| Missing value processing. (0) | 2020.06.27 |
| Data filtering (0) | 2020.06.16 |



