이번 시간에는 pandas의 groupby 함수를 사용해 여러 가지 작업을 수행해보겠습니다.
매번 느끼는 거지만 분석할 때 groupby는 정말 자주 사용하는 것 같아 그 중요성을 느껴 블로그를 통해서 정리해보고 싶었어요!.
그럼 바로 시작해볼까요??
첫 번째로, groupby는 시각화를 할 때 조건을 추가할 수 있습니다.

만약, 주택 가격을 예측하는 데이터 셋이 있다면
Suburb의 value_counts() 함수를 적용해서 상위 15개의 suburb를 count 해 출력할 수 있습니다.
e = df['Suburb'].value_counts()[:15]
sns.barplot(y=e.index, x=e)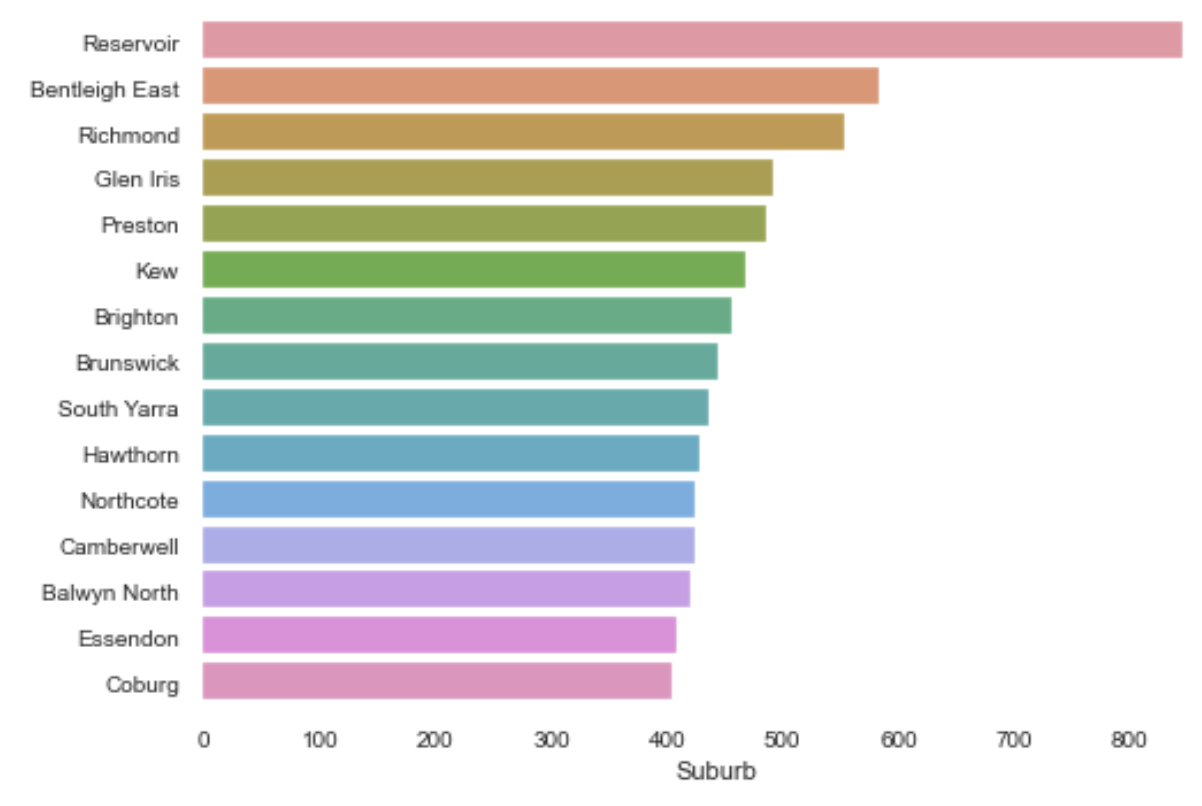
이렇게요!.
하지만 여기서 가격 순으로 Suburb를 순위대로 나열하고 싶다면
sub = df.groupby('Suburb')['Price'].median().sort_values(ascending=False)[:15]
sns.barplot(y=sub.index, x=sub)
위와 같이 그루핑을 해서 중간값(median)으로 상위 15개를 출력할 수 있습니다.!

어렵지 않죠?!
자, 그럼 두 번째로 넘어가 볼까요?
두 번째로, groupby는 한 column을 index로 지정해서 나머지 columns에 대한 통계를 낼 수도 있습니다. (만약 index로 추가하기를 원하지 않다면 as_index=False를 groupby의 parameter로 지정할 수 있습니다.)
w = df.groupby("Type").median() 
agg 함수를 사용하면 조건을 추가할 수 있습니다.
p = df.groupby('Rooms')['Rooms'].agg(['sum','mean','std'])
p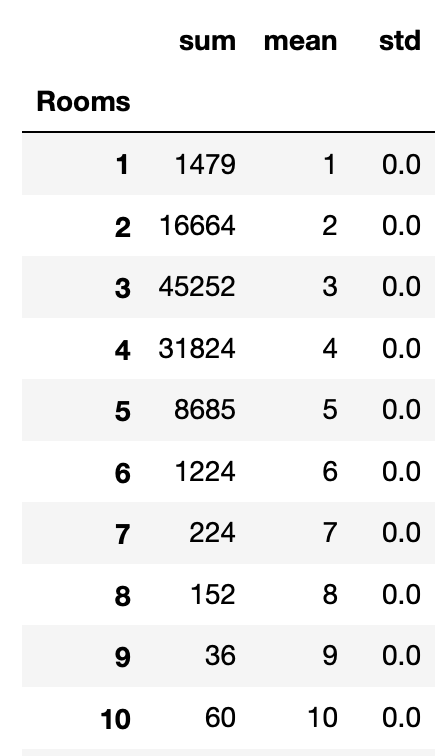
이렇게요!
다음은 apply 함수와 함께 써보겠습니다. apply함수도 여러 가지 형태로 사용될 수 있는데요. 다음 시간에 apply 함수를 주제로 한번 정리해보겠습니다.
e = df.groupby("Type")['Method'].apply(lambda x: ','.join(x)).to_frame()
e
여러 종류의 Method를 type에 , 로 구분해 넣었습니다.
가령, Method의 nunique 함수를 찍어보고 싶다면
df.groupby("Type")["Method"].nunique().to_frame()
이렇게 groupby와 같이 사용할 수도 있습니다.
그럼 이상으로 마치겠습니다.!
감사합니다.ㅎㅎㅎ
'Python skills for Data Analysis' 카테고리의 다른 글
| [Functions] apply(lambda x :) examples (0) | 2020.08.15 |
|---|---|
| Data Visualization(데이터 시각화) (0) | 2020.07.14 |
| Missing value processing. (0) | 2020.06.27 |
| Data filtering (0) | 2020.06.16 |



